
Introduction
CloudStack usage is a complimentary service which tracks end user consumption of CloudStack resources and summarises this in a separate database for reporting or billing. The usage database can be queried directly, through the CloudStack API, or it can be integrated into external billing or reporting systems.
For background information on the usage service please refer to the CloudStack documentation set:
- http://docs.cloudstack.apache.org/projects/cloudstack-installation/en/4.9/optional_installation.html
- http://docs.cloudstack.apache.org/projects/cloudstack-administration/en/4.9/usage.html
In this blog post we will go a step further and deep dive into how the usage service works, how you can run usage reports from the database either directly or through the API, and also how to troubleshoot this.
Please note – in this blog post we will be discussing the underlying database structure for the CloudStack management and usage services. Whilst these have separate databases they do in some cases share table names – hence please note the databases referenced throughout – e.g. cloud.usage_event versus cloudstack_usage.usage_event, etc.
Configuration
Installation
As per the official CloudStack documentation the usage service is simply installed and started. In CentOS/RHEL this is done as follows:
# yum install cloudstack-usage # chkconfig cloudstack-usage on # service cloudstack-usage on
whilst on a Debian/Ubuntu server:
# apt-get install cloudstack-usage # update-rc.d cloudstack-usage defaults # service cloudstack-usage on
Once configure the usage service will use the same MySQL connection details as the main CloudStack management service. This is automatically added when the management service is configured with the “cloudstack-setup-databases” script (refer to http://docs.cloudstack.apache.org/projects/cloudstack-installation/en/4.9/management-server/index.html). The usage service installation simply adds a symbolic link to the same db.properties file as is used by cloudstack-management:
# ls -l /etc/cloudstack/usage/ total 4 lrwxrwxrwx. 1 root root 40 Sep 8 08:18 db.properties > /etc/cloudstack/management/db.properties lrwxrwxrwx. 1 root root 30 Sep 8 08:18 key > /etc/cloudstack/management/key -rw-r--r--. 1 root root 2968 Jul 12 10:36 log4j-cloud.xml
Please note whilst the cloudstack-usage and cloudstack-management service share the same db.properties configuration file this will still contain individual settings for each service:
# grep -i usage /etc/cloudstack/usage/db.properties db.usage.maxActive=100 # usage database tuning parameters db.usage.maxWait=10000 db.usage.maxIdle=30 db.usage.name=cloud_usage db.usage.port=3306 # usage database settings db.usage.failOverReadOnly=false db.usage.host=(Usage DB host IP address) db.usage.password=ENC(Encrypted password) db.usage.initialTimeout=3600 db.usage.username=cloud db.usage.autoReconnect=true db.usage.url.params= db.usage.driver=jdbc:mysql #usage Database db.usage.reconnectAtTxEnd=true db.usage.queriesBeforeRetryMaster=5000 db.usage.slaves=localhost,localhost db.usage.autoReconnectForPools=true db.usage.secondsBeforeRetryMaster=3600
Note the above settings would need changed if:
- the usage DB is installed on a different MySQL server than the main CloudStack database
- if the usage database is using a different set of login credentials
Also note that the passwords in the file above are encrypted using the method specified during the “cloudstack-setup-databases” script run – hence this also uses the referenced “key” file as shown in the above folder listing.
Application settings
Once installed the usage service is configured with the following global settings in CloudStack:
- enable.usage.server:
- Switches usage service on/off
- true|false
- usage.aggregation.timezone:
- Timezone used for usage aggregation.
- Refer to http://docs.cloudstack.apache.org/en/latest/dev.html for formatting.
- Defaults to “GMT”.
- usage.execution.timezone:
- Timezone for usage job execution.
- Refer to http://docs.cloudstack.apache.org/en/latest/dev.html for formatting.
- usage.sanity.check.interval:
- Interval (in days) to check sanity of usage data.
- usage.snapshot.virtualsize.select:
- Set the value to true if snapshot usage need to consider virtual size, else physical size is considered.
- true|false – defaults to false.
- usage.stats.job.aggregation.range:
- The range of time for aggregating the user statistics specified in minutes (e.g. 1440 for daily, 60 for hourly. Default is 60 minutes).
- Please note this setting would be changed in a chargeback situation where VM resources are charged on an hourly/daily/monthly basis.
- usage.stats.job.exec.time:
- The time at which the usage statistics aggregation job will run as an HH:MM time, e.g. 00:30 to run at 12:30am.
- Default is 00:15.
- Please note this time follows the setting in usage.execution.timezone above.
Please note – if any of these settings are updated then only the cloudstack-usage service needs restarted (i.e. there is no need to restart cloudstack-management).
Usage types
To track the resources utilised in CloudStack every API call where a resource is created, destroyed, stopped, started, requested and released are tracked in the cloud.usage_event table. This table has entries for every event since the start of the CloudStack instance creation, hence may grow to become quite big.
During processing every event in this table are assigned a usage type. The usage types are listed in the CloudStack documentation http://docs.cloudstack.apache.org/projects/cloudstack-administration/en/4.9/usage.html#usage-types, or it can simply be queried using the CloudStack “listUsagetypes” API call:
# cloudmonkey list usagetypes count = 19 usagetype: +-------------+-----------------------------------------+ | usagetypeid | description | +-------------+-----------------------------------------+ | 1 | Running Vm Usage | | 2 | Allocated Vm Usage | | 3 | IP Address Usage | | 4 | Network Usage (Bytes Sent) | | 5 | Network Usage (Bytes Received) | | 6 | Volume Usage | | 7 | Template Usage | | 8 | ISO Usage | | 9 | Snapshot Usage | | 10 | Security Group Usage | | 11 | Load Balancer Usage | | 12 | Port Forwarding Usage | | 13 | Network Offering Usage | | 14 | VPN users usage | | 21 | VM Disk usage(I/O Read) | | 22 | VM Disk usage(I/O Write) | | 23 | VM Disk usage(Bytes Read) | | 24 | VM Disk usage(Bytes Write) | | 25 | VM Snapshot storage usage | +-------------+-----------------------------------------+
Please note these usage types are calculated depending on the nature of resource used, e.g.:
- “Running VM usage” will simply count the hours a single VM instance is used.
- “Volume usage” will however track both the size of each volume in addition to the time utilised.
Process flow
Overview
From a high level point of view the usage service processes data already generated by the CloudStack management service, copies this to the cloud_usage database before processing and aggregating the data in the cloud_usage.cloud_usage database:
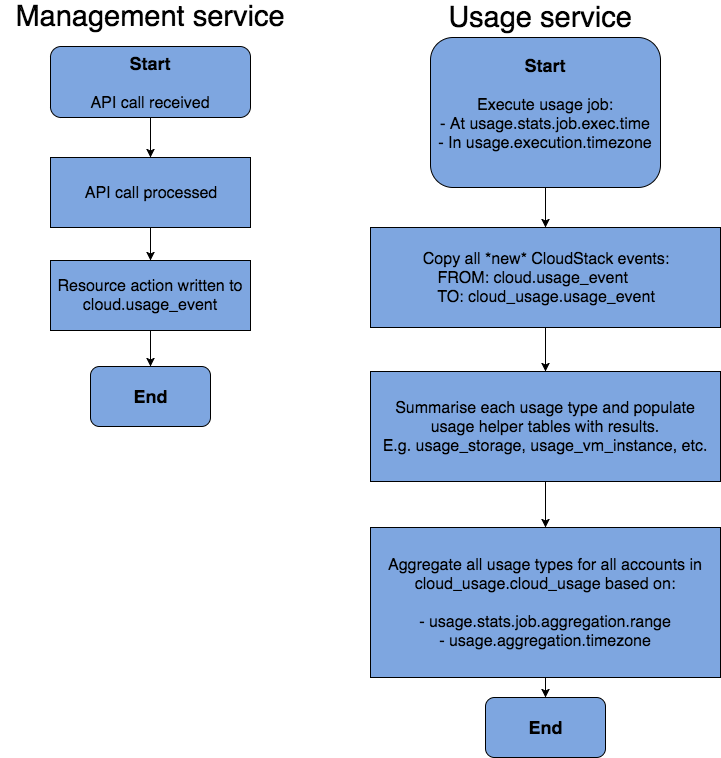
Details
Using a running VM instance as example the data process flow is as follows.
Usage_event table entries
CloudStack management writes all events to the cloud.usage_event table. This happens whether the cloudstack-usage service is running or not.
In this example we will track the VM with instance ID 17. The resource tracked – be it a VM, a volume, a port forwarding rule , etc. – is listed in the usage_event table as “resource_id”, which points to the main ID field in the vm_instance, volume tables etc.
SELECT * FROM cloud.usage_event WHERE type like '%VM%' and resource_id=17;
| id | type | account_id | created | zone_id | resource_id | resource_name | offering_id | template_id | size | resource_type | processed | virtual_size |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 68 | VM.CREATE | 6 | 2017-09-08 11:14:31 | 1 | 17 | bbannervm12 | 17 | 5 | NULL | XenServer | 0 | NULL |
| 70 | VM.START | 6 | 2017-09-08 11:14:41 | 1 | 17 | bbannervm12 | 17 | 5 | NULL | XenServer | 0 | NULL |
| 123 | VM.STOP | 6 | 2017-09-26 13:44:48 | 1 | 17 | bbannervm12 | 17 | 5 | NULL | XenServer | 0 | NULL |
| 125 | VM.DESTROY | 6 | 2017-09-26 13:45:00 | 1 | 17 | bbannervm12 | 17 | 5 | NULL | XenServer | 0 | NULL |
Please note: a lot of the resources will obviously still be in use – i.e. they will not have a destroy/release entry. In this case the usage service considers the end date to be open, i.e. all calculations are up until today.
Usage_event copy
When the usage job runs (at “usage.stats.job.exec.time”) it first copies all new entries since the last processing time from the cloud.usage_event table to the cloud_usage.usage_event table.
The only difference between the two tables is the “processed” column – in the cloud database this is always set to 0 – nil, however once the table entry is processed in the cloud_usage database this field is updated to 1.
In comparison – the entries in the cloud database:
SELECT * FROM cloud.usage_event WHERE id > 130;
| id | type | account_id | created | zone_id | resource_id | resource_name | offering_id | template_id | size | resource_type | processed | virtual_size |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 131 | VOLUME.CREATE | 6 | 2017-09-26 13:45:44 | 1 | 31 | bbannerdata3 | 6 | NULL | 2147483648 | NULL | 0 | NULL |
| 132 | NET.IPASSIGN | 6 | 2017-09-26 13:46:05 | 1 | 17 | 10.1.34.77 | NULL | 0 | 0 | VirtualNetwork | 0 | NULL |
| 133 | VM.STOP | 8 | 2017-09-28 10:31:44 | 1 | 23 | secretprojectvm1 | 17 | 5 | NULL | XenServer | 0 | NULL |
| 134 | NETWORK.OFFERING.REMOVE | 8 | 2017-09-28 10:31:44 | 1 | 23 | 41 | 8 | NULL | 0 | NULL | 0 | NULL |
Compared to the same entries in cloud_usage:
SELECT * FROM cloud_usage.usage_event WHERE id > 130;
| id | type | account_id | created | zone_id | resource_id | resource_name | offering_id | template_id | size | resource_type | processed | virtual_size |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 131 | VOLUME.CREATE | 6 | 2017-09-26 13:45:44 | 1 | 31 | bbannerdata3 | 6 | NULL | 2147483648 | NULL | 1 | NULL |
| 132 | NET.IPASSIGN | 6 | 2017-09-26 13:46:05 | 1 | 17 | 10.1.34.77 | NULL | 0 | 0 | VirtualNetwork | 1 | NULL |
| 133 | VM.STOP | 8 | 2017-09-28 10:31:44 | 1 | 23 | secretprojectvm1 | 17 | 5 | NULL | XenServer | 1 | NULL |
| 134 | NETWORK.OFFERING.REMOVE | 8 | 2017-09-28 10:31:44 | 1 | 23 | 41 | 8 | NULL | 0 | NULL | 1 | NULL |
Account copy
As part of this copy job the cloudstack-usage service will also make a copy of some of the columns in the cloud.account table such that a ownership of resources can be easily established during processing.
Usage summary and helper tables
In the first usage aggregation step all usage data per account and per usage type is summarised in helper tables. Continuing the example above the CREATE+DESTROY events as well as the VM START+STOP events are summarised in the “usage_vm_instance” table:
SELECT * FROM cloud_usage.usage_vm_instance WHERE vm_instance_id=17;
| usage_type | zone_id | account_id | vm_instance_id | vm_name | service_offering_id | template_id | hypervisor_type | start_date | end_date | cpu_speed | cpu_cores | memory |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 6 | 17 | bbannervm12 | 17 | 5 | XenServer | 2017-09-08 11:14:41 | 2017-09-26 13:44:48 | NULL | NULL | NULL |
| 2 | 1 | 6 | 17 | bbannervm12 | 17 | 5 | XenServer | 2017-09-08 11:14:31 | 2017-09-26 13:45:00 | NULL | NULL | NULL |
Note the helper table has now summarised the data with the usage type mentioned above – and the start/end dates are contained in the same database row.
Please note – if a resource is still in use then the end date simply isn’t populated, i.e. all calculations will work on rolling end date of today.
If we now also compare the volume used by VM instance ID 17 we find this in the cloud_usage.usage_volume helper table:
SELECT usage_volume.* FROM cloud_usage.usage_volume LEFT JOIN cloud.volumes ON (usage_volume.id = volumes.id) WHERE cloud.volumes.instance_id = 17;
| id | zone_id | account_id | domain_id | disk_offering_id | template_id | size | created | deleted |
|---|---|---|---|---|---|---|---|---|
| 18 | 1 | 6 | 2 | NULL | 5 | 21474836480 | 2017-09-08 11:14:31 | 2017-09-26 13:45:00 |
As the database selects above show – each helper table will contain only the information pertinent to that specific usage type, hence the cloud_usage.usage_vm_instance contains information about VM service offering, template and hypervisor type the cloud_usage.usage_volume contains information about disk offering ID, template ID and size.
If a usage type for a resource has been started/stopped or requested/released multiple times then each period of use will be listed in the helper tables:
SELECT * FROM cloud_usage.usage_vm_instance WHERE vm_instance_id=12;
| usage_type | zone_id | account_id | vm_instance_id | vm_name | service_offering_id | template_id | hypervisor_type | start_date | end_date | cpu_speed | cpu_cores | memory |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 6 | 12 | bbannervm2 | 17 | 5 | XenServer | 2017-09-08 09:30:37 | 2017-09-08 09:30:49 | NULL | NULL | NULL |
| 1 | 1 | 6 | 12 | bbannervm2 | 17 | 5 | XenServer | 2017-09-08 11:14:03 | NULL | NULL | NULL | NULL |
| 2 | 1 | 6 | 12 | bbannervm2 | 17 | 5 | XenServer | 2017-09-08 09:30:20 | NULL | NULL | NULL | NULL |
Usage data aggregation
Once all helper tables have been populated the usage service now creates time aggregated database entries in the cloud_usage.cloud_usage table. In all simplicity this process:
- Analyses all entries in the helper tables.
- Splits up this data based on “usage.stats.job.aggregation.range” to create individual usage timeblocks.
- Repeats this process for all accounts and for all resources.
So – looking at the VM with ID=17 analysed above:
- This had a running start date of 2017-09-08 11:14:41, an end date of 2017-09-26 13:44:48.
- The usage service is set up with usage.stats.job.aggregation.range=1440, i.e. 24 hours.
- The usage service will now create entries in the cloud_usage.cloud_usage table for every full and partial 24 hour period this VM was running.
SELECT * FROM cloud_usage.cloud_usage WHERE usage_id=17 and usage_type=1;
| id | zone_id | account_id | domain_id | description | usage_display | usage_type | raw_usage | vm_instance_id | vm_name | offering_id | template_id | usage_id | type | size | network_id | start_date | end_date | virtual_size | cpu_speed | cpu_cores | memory | quota_calculated |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 64 | 1 | 6 | 2 | bbannervm12 running time (ServiceOffering: 17) (Template: 5) | 12.755278 Hrs | 1 | 12.755277633666992 | 17 | bbannervm12 | 17 | 5 | 17 | XenServer | NULL | NULL | 2017-09-08 00:00:00 | 2017-09-08 23:59:59 | NULL | NULL | NULL | NULL | 0 |
| 146 | 1 | 6 | 2 | bbannervm12 running time (ServiceOffering: 17) (Template: 5) | 24 Hrs | 1 | 24 | 17 | bbannervm12 | 17 | 5 | 17 | XenServer | NULL | NULL | 2017-09-09 00:00:00 | 2017-09-09 23:59:59 | NULL | NULL | NULL | NULL | 0 |
| 221 | 1 | 6 | 2 | bbannervm12 running time (ServiceOffering: 17) (Template: 5) | 24 Hrs | 1 | 24 | 17 | bbannervm12 | 17 | 5 | 17 | XenServer | NULL | NULL | 2017-09-10 00:00:00 | 2017-09-10 23:59:59 | NULL | NULL | NULL | NULL | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1271 | 1 | 6 | 2 | bbannervm12 running time (ServiceOffering: 17) (Template: 5) | 24 Hrs | 1 | 24 | 17 | bbannervm12 | 17 | 5 | 17 | XenServer | NULL | NULL | 2017-09-24 00:00:00 | 2017-09-24 23:59:59 | NULL | NULL | NULL | NULL | 0 |
| 1346 | 1 | 6 | 2 | bbannervm12 running time (ServiceOffering: 17) (Template: 5) | 24 Hrs | 1 | 24 | 17 | bbannervm12 | 17 | 5 | 17 | XenServer | NULL | NULL | 2017-09-25 00:00:00 | 2017-09-25 23:59:59 | NULL | NULL | NULL | NULL | 0 |
| 1427 | 1 | 6 | 2 | bbannervm12 running time (ServiceOffering: 17) (Template: 5) | 13.746667 Hrs | 1 | 13.74666690826416 | 17 | bbannervm12 | 17 | 5 | 17 | XenServer | NULL | NULL | 2017-09-26 00:00:00 | 2017-09-26 23:59:59 | NULL | NULL | NULL | NULL | 0 |
Since all of these entries are split into specific dates it is now relatively straight forward to run a report to capture all resource usage for an account over a specific time period, e.g. if a monthly bill is required.
Querying usage data through the API
The usage records can also be queried through the API by using the “listUsagerecords” API call. This uses similar syntax to the above – but there are some differences:
- The API call requires start and end dates, these are in a “yyyy-MM-dd HH:mm:ss” or simply a “yyyy-MM-dd” format.
- The usage type is same as above, e.g. type=1 for running VMs.
- Usage ID is however the UUID attached to the resource in question, e.g. in the following example VM ID 17 actually has UUID 4358f436-bc9b-4793-b1be-95fa9b074fd5 in the vm_instance table.
- The API call can also be filtered for account/accountid/domain.
More information on the syntax can be found in http://cloudstack.apache.org/api/apidocs-4.9/apis/listUsageRecords.html .
The following API query will list the first three day’s worth of usage data listed in the table above:
# cloudmonkey list usagerecords type=1 startdate=2017-09-09 enddate=2017-09-10 usageid=4358f436-bc9b-4793-b1be-95fa9b074fd5 count = 3 usagerecord: +-----------------------------+---------+--------------------------------------+-----------------------------+--------------------------------------------------------------+-------------+--------------------------------------+--------------------------------------+-----------+------------+--------------------------------------+----------+--------------------------------------+---------------+--------------------------------------+-----------+--------------------------------------+ | startdate | account | domainid | enddate | description | name | virtualmachineid | offeringid | usagetype | domain | zoneid | rawusage | templateid | usage | usageid | type | accountid | +-----------------------------+---------+--------------------------------------+-----------------------------+--------------------------------------------------------------+-------------+--------------------------------------+--------------------------------------+-----------+------------+--------------------------------------+----------+--------------------------------------+---------------+--------------------------------------+-----------+--------------------------------------+ | 2017-09-08'T'00:00:00+00:00 | bbanner | f3501b29-01f7-44ce-a266-9e3f12c17394 | 2017-09-08'T'23:59:59+00:00 | bbannervm12 running time (ServiceOffering: 17) (Template: 5) | bbannervm12 | 4358f436-bc9b-4793-b1be-95fa9b074fd5 | 60d9aaf1-7ff7-472e-b29f-6768d0cb5702 | 1 | Subdomain1 | d4b9d32e-d779-48b8-814d-d7847d55a684 | 12.755278| 47dd8c98-946e-11e7-b419-0666ae010714 | 12.755278 Hrs | 4358f436-bc9b-4793-b1be-95fa9b074fd5 | XenServer | 8c2d592f-78e1-4e92-a910-1e4b865240cf | | 2017-09-09'T'00:00:00+00:00 | bbanner | f3501b29-01f7-44ce-a266-9e3f12c17394 | 2017-09-09'T'23:59:59+00:00 | bbannervm12 running time (ServiceOffering: 17) (Template: 5) | bbannervm12 | 4358f436-bc9b-4793-b1be-95fa9b074fd5 | 60d9aaf1-7ff7-472e-b29f-6768d0cb5702 | 1 | Subdomain1 | d4b9d32e-d779-48b8-814d-d7847d55a684 | 24 | 47dd8c98-946e-11e7-b419-0666ae010714 | 24 Hrs | 4358f436-bc9b-4793-b1be-95fa9b074fd5 | XenServer | 8c2d592f-78e1-4e92-a910-1e4b865240cf | | 2017-09-10'T'00:00:00+00:00 | bbanner | f3501b29-01f7-44ce-a266-9e3f12c17394 | 2017-09-10'T'23:59:59+00:00 | bbannervm12 running time (ServiceOffering: 17) (Template: 5) | bbannervm12 | 4358f436-bc9b-4793-b1be-95fa9b074fd5 | 60d9aaf1-7ff7-472e-b29f-6768d0cb5702 | 1 | Subdomain1 | d4b9d32e-d779-48b8-814d-d7847d55a684 | 24 | 47dd8c98-946e-11e7-b419-0666ae010714 | 24 Hrs | 4358f436-bc9b-4793-b1be-95fa9b074fd5 | XenServer | 8c2d592f-78e1-4e92-a910-1e4b865240cf | +-----------------------------+---------+--------------------------------------+-----------------------------+--------------------------------------------------------------+-------------+--------------------------------------+--------------------------------------+-----------+------------+--------------------------------------+----------+--------------------------------------+---------------+--------------------------------------+-----------+--------------------------------------+
Analysing and reporting on usage data
The usage data can be analysed in any reporting tool – from the various CloudStack billing platforms, to enterprise billing systems as well as simpler tools like Excel. Since the cloud_usage.cloud_usage data is fully aggregated into time utilised blocks, it is now just a question of summarising data based on usage type, accounts, service offerings, etc.
The following SQL queries are provided as examples only – in a real use case these will most likely require to be changed and refined to the specific reporting requirements.
Running VMs
To find usage data for all running VMs run during the month of September we search for usage type=1 and group by vm_instance. For a VM instance we summarise how many hours each VM has been running – however in a real billing scenario this would most likely also be broken down into e.g. how many hours of VM usage has been utilised per VM service offering.
SELECT account_id, account_name, usage_type, offering_id, vm_instance_id, vm_name, SUM(raw_usage) as VMRunHours FROM cloud_usage.cloud_usage LEFT JOIN cloud_usage.account on (cloud_usage.account_id = account.id) WHERE start_date LIKE '2017-09%' AND usage_type = 1 GROUP BY vm_instance_id ORDER BY account_id ASC, vm_instance_id ASC;
| account_id | account_name | usage_type | offering_id | vm_instance_id | vm_name | VMRunHours |
|---|---|---|---|---|---|---|
| 2 | admin | 1 | 1 | 3 | rootvm1 | 3.0205559730529785 |
| 2 | admin | 1 | 17 | 20 | rootvm2 | 539.7991666793823 |
| 4 | pparker | 1 | 17 | 5 | pparkervm1 | 542.5497226715088 |
| 4 | pparker | 1 | 17 | 14 | pparkervm5 | 0.26527804136276245 |
| 4 | pparker | 1 | 17 | 15 | pparkervm7 | 0.2247224897146225 |
| 4 | pparker | 1 | 17 | 16 | pparkervm16 | 540.774167060852 |
| 4 | pparker | 1 | 17 | 22 | ppvpcvm1000 | 539.7311105728149 |
| 5 | ckent | 1 | 17 | 7 | ckentvm1 | 5.246944904327393 |
| 5 | ckent | 1 | 17 | 9 | ckentvm2 | 435.4169445037842 |
| 5 | ckent | 1 | 17 | 18 | ckentvm23 | 0.8186113834381104 |
| 5 | ckent | 1 | 17 | 25 | ckentvm30 | 106.28194522857666 |
| 6 | bbanner | 1 | 17 | 10 | bbannervm1 | 1.7469446659088135 |
| 6 | bbanner | 1 | 17 | 12 | bbannervm2 | 540.7691669464111 |
| 6 | bbanner | 1 | 17 | 17 | bbannervm12 | 434.50194454193115 |
| 6 | bbanner | 1 | 17 | 26 | bbannervm30 | 106.24055576324463 |
| 8 | PrjAcct-SecretProject-1 | 1 | 17 | 23 | secretprojectvm1 | 477.4819440841675 |
Network utilisation
The following will summarise network usage for sent (usage type=4) and received (usage type=5) traffic on a per account basis, again this is listing for the month of September.
For network utilisation the usage is simply summarised as total Bytes sent or received:
SELECT account_id, account_name, usage_type, network_id, SUM(raw_usage) as TotalBytes FROM cloud_usage.cloud_usage LEFT JOIN cloud_usage.account on (cloud_usage.account_id = account.id) WHERE start_date LIKE '2017-09%' AND usage_type in (4,5) GROUP BY account_id, usage_type ORDER BY account_id ASC;
| account_id | account_name | usage_type | network_id | TotalBytes |
|---|---|---|---|---|
| 2 | admin | 4 | 204 | 391320 |
| 2 | admin | 5 | 204 | 1744 |
| 4 | pparker | 4 | 200 | 164764260 |
| 4 | pparker | 5 | 200 | 163779643 |
| 5 | ckent | 4 | 206 | 391500 |
| 5 | ckent | 5 | 206 | 0 |
| 6 | bbanner | 4 | 207 | 776700 |
| 6 | bbanner | 5 | 207 | 0 |
| 8 | PrjAcct-SecretProject-1 | 4 | 211 | 343080 |
| 8 | PrjAcct-SecretProject-1 | 5 | 211 | 0 |
Volume utilisation
For volume or general storage utilisation (applies to snapshots as well) the usage is calculated as storage hours – e.g. GbHours. In this example we again summarise for all volumes (usage type=6) on a per account and disk basis during the month of September. Please note in this case we have to do multiple joins (or nested WHERE statements) to look up volume IDs, VM name, etc.
SELECT cloud_usage.cloud_usage.account_id, cloud_usage.account.account_name, cloud_usage.cloud_usage.usage_type, cloud_usage.cloud_usage.usage_id, cloud.vm_instance.name as Instance_Name, cloud.volumes.name as Volume_Name, cloud_usage.cloud_usage.size/(1024*1024*1024) as DiskSizeGb, SUM(cloud_usage.cloud_usage.raw_usage) as TotalHours, sum(cloud_usage.cloud_usage.raw_usage*cloud_usage.cloud_usage.size/(1024*1024*1024)) as GbHours FROM cloud_usage.cloud_usage LEFT JOIN cloud_usage.account on (cloud_usage.account_id = account.id) LEFT JOIN cloud.volumes on (cloud_usage.usage_id = volumes.id) LEFT JOIN cloud.vm_instance on (cloud.volumes.instance_id = cloud.vm_instance.id) WHERE start_date LIKE '2017-09%' AND usage_type = 6 GROUP BY usage_id ORDER BY account_id ASC, usage_id ASC;
| account_id | account_name | usage_type | usage_id | Instance_Name | Volume_Name | DiskSizeGb | TotalHours | GbHours |
|---|---|---|---|---|---|---|---|---|
| 2 | admin | 6 | 3 | rootvm1 | ROOT-3 | 20.0000 | 542.8836107254028 | 10857.672214508057 |
| 2 | admin | 6 | 23 | rootvm2 | ROOT-20 | 20.0000 | 539.8033332824707 | 10796.066665649414 |
| 4 | pparker | 6 | 5 | pparkervm1 | ROOT-5 | 20.0000 | 542.6494445800781 | 10852.988891601562 |
| 4 | pparker | 6 | 15 | pparkervm5 | ROOT-14 | 20.0000 | 541.0441675186157 | 10820.883350372314 |
| 4 | pparker | 6 | 16 | pparkervm7 | ROOT-15 | 20.0000 | 0.2291669398546219 | 4.583338797092438 |
| 4 | pparker | 6 | 17 | pparkervm16 | ROOT-16 | 20.0000 | 540.7772226333618 | 10815.544452667236 |
| 4 | pparker | 6 | 25 | ppvpcvm1000 | ROOT-22 | 20.0000 | 539.7355556488037 | 10794.711112976074 |
| 5 | ckent | 6 | 7 | ckentvm1 | ROOT-7 | 20.0000 | 436.3361120223999 | 8726.722240447998 |
| 5 | ckent | 6 | 9 | ckentvm2 | ROOT-9 | 20.0000 | 542.5586109161377 | 10851.172218322754 |
| 5 | ckent | 6 | 20 | ckentvm23 | ROOT-18 | 20.0000 | 434.36277770996094 | 8687.255554199219 |
| 5 | ckent | 6 | 22 | NULL | ckentdata1 | 2.0000 | 540.651388168335 | 1081.30277633667 |
| 5 | ckent | 6 | 29 | ckentvm30 | ROOT-25 | 20.0000 | 106.28638935089111 | 2125.7277870178223 |
| 6 | bbanner | 6 | 10 | bbannervm1 | ROOT-10 | 20.0000 | 1.771389126777649 | 35.42778253555298 |
| 6 | bbanner | 6 | 12 | bbannervm2 | ROOT-12 | 20.0000 | 542.4944448471069 | 10849.888896942139 |
| 6 | bbanner | 6 | 13 | bbannervm2 | bbannerdatadisk1 | 2.0000 | 542.305832862854 | 1084.611665725708 |
| 6 | bbanner | 6 | 18 | bbannervm12 | ROOT-17 | 20.0000 | 434.5080556869507 | 8690.161113739014 |
| 6 | bbanner | 6 | 19 | bbannervm2 | bbannerdata2 | 5.0000 | 540.7536115646362 | 2703.768057823181 |
| 6 | bbanner | 6 | 30 | bbannervm30 | ROOT-26 | 20.0000 | 106.24472236633301 | 2124.89444732666 |
| 6 | bbanner | 6 | 31 | bbannervm30 | bbannerdata3 | 2.0000 | 106.23777770996094 | 212.47555541992188 |
| 8 | PrjAcct-SecretProject-1 | 6 | 26 | secretprojectvm1 | ROOT-23 | 20.0000 | 538.975832939148 | 10779.516658782959 |
| 8 | PrjAcct-SecretProject-1 | 6 | 28 | secretprojectvm1 | secretprojectdata1 | 2.0000 | 538.7525005340576 | 1077.5050010681152 |
IP addresses, port forwarding rules and VPN users
For other usage types where – similar to VM running hours – we simply report on the total hours utilised we again summarise the raw_usage, but since the description in cloud_usage.cloud.usage is clear enough we don’t need to go looking elsewhere for this information. In the following example we report on IP address usage (usage type=3), port forwarding rules (12) and VPN users (14):
SELECT cloud_usage.cloud_usage.account_id, cloud_usage.account.account_name, cloud_usage.cloud_usage.usage_type, cloud_usage.cloud_usage.usage_id, cloud_usage.cloud_usage.description, SUM(cloud_usage.cloud_usage.raw_usage) as TotalHours FROM cloud_usage.cloud_usage LEFT JOIN cloud_usage.account on (cloud_usage.account_id = account.id) WHERE start_date LIKE '2017-09%' AND usage_type in (3,12,14) GROUP BY description ORDER BY account_id ASC, usage_id ASC;
| account_id | account_name | usage_type | usage_id | description | TotalHours |
|---|---|---|---|---|---|
| 2 | admin | 3 | 3 | IPAddress: 10.1.34.63 | 542.8833332061768 |
| 4 | pparker | 3 | 4 | IPAddress: 10.1.34.64 | 542.648889541626 |
| 4 | pparker | 3 | 13 | IPAddress: 10.1.34.73 | 539.7686109542847 |
| 5 | ckent | 3 | 5 | IPAddress: 10.1.34.65 | 542.6322221755981 |
| 5 | ckent | 3 | 6 | IPAddress: 10.1.34.66 | 542.5547218322754 |
| 5 | ckent | 3 | 7 | IPAddress: 10.1.34.67 | 542.5541667938232 |
| 5 | ckent | 3 | 10 | IPAddress: 10.1.34.70 | 540.6561107635498 |
| 5 | ckent | 3 | 11 | IPAddress: 10.1.34.71 | 540.2247219085693 |
| 5 | ckent | 3 | 12 | IPAddress: 10.1.34.72 | 540.0552778244019 |
| 5 | ckent | 3 | 16 | IPAddress: 10.1.34.76 | 106.27805614471436 |
| 6 | bbanner | 14 | 1 | VPN User: bbannervpn1, Id: 1 usage time | 542.4766664505005 |
| 6 | bbanner | 14 | 2 | VPN User: brucesdogvpn1, Id: 2 usage time | 1.7355557680130005 |
| 6 | bbanner | 14 | 3 | VPN User: bruceswifevpn1, Id: 3 usage time | 540.7405557632446 |
| 6 | bbanner | 14 | 4 | VPN User: stanleevpn1, Id: 4 usage time | 540.7180547714233 |
| 6 | bbanner | 3 | 8 | IPAddress: 10.1.34.68 | 542.529444694519 |
| 6 | bbanner | 12 | 9 | Port Forwarding Rule: 9 usage time | 1.6469446420669556 |
| 6 | bbanner | 3 | 9 | IPAddress: 10.1.34.69 | 542.4852771759033 |
| 6 | bbanner | 3 | 17 | IPAddress: 10.1.34.77 | 106.2319450378418 |
| 8 | PrjAcct-SecretProject-1 | 3 | 14 | IPAddress: 10.1.34.74 | 538.9755554199219 |
| 8 | PrjAcct-SecretProject-1 | 3 | 15 | IPAddress: 10.1.34.75 | 538.7594442367554 |
Troubleshooting
Service management
As described earlier in this blog post the usage job will run at a time specified in the usage.stats.job.exec.time global setting.
Once the job has ran it will update its own internal database with the run time and the start/end times processed:
SELECT * FROM cloud_usage.usage_job;
| id | host | pid | job_type | scheduled | start_millis | end_millis | exec_time | start_date | end_date | success | heartbeat |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | acshostname/192.168.10.10 | 23589 | 0 | 0 | 1504828800000 | 1504915199999 | 2072 | 2017-09-08 00:00:00 | 2017-09-08 23:59:59 | 1 | 2017-09-09 00:14:53 |
| 2 | acshostname/192.168.10.10 | 23589 | 0 | 0 | 1504915200000 | 1505001599999 | 607 | 2017-09-09 00:00:00 | 2017-09-09 23:59:59 | 1 | 2017-09-10 00:14:53 |
| 3 | acshostname/192.168.10.10 | 23589 | 0 | 0 | 1505001600000 | 1505087999999 | 536 | 2017-09-10 00:00:00 | 2017-09-10 23:59:59 | 1 | 2017-09-11 00:14:53 |
| 4 | acshostname/192.168.10.10 | 23589 | 0 | 0 | 1505088000000 | 1505174399999 | 503 | 2017-09-11 00:00:00 | 2017-09-11 23:59:59 | 1 | 2017-09-12 00:14:53 |
| 5 | acshostname/192.168.10.10 | 23589 | 0 | 0 | 1505174400000 | 1505260799999 | 509 | 2017-09-12 00:00:00 | 2017-09-12 23:59:59 | 1 | 2017-09-13 00:14:53 |
A couple of things to note on this lists:
- Start_millis and end_millis simply list the epoch timestamp in start_date and end_date. The epoch time is used by the usage service to determine cloud_usage.cloud_usage entries.
- Exec_time will list how long the usage job ran for. This is useful in cases where the usage job processing time is longer than 24 hours – i.e. where usage job schedules may start overlapping.
- The success field is set to 1 for success, 0 for failure.
- Heartbeat lists when the job was ran.
When the cloudstack-usage service is restarted this will run checks against the usage_jobs table to determine:
- If the last scheduled job was ran. If this wasn’t done the job is ran again, i.e. a service startup will run a single missed job.
- Thereafter the usage job will run at its normal scheduled time.
Usage troubleshooting – general advice
Since this blog post covers topics around adding/updating/removing entries in the cloud and cloud_usage databases we always advise CloudStack users to take MySQL dumps of both databases before doing any work – whether this directly in MySQL or via the usage API calls.
Database inconsistencies
Under certain circumstances (e.g. if the cloudstack-management service crashes) the cloud.usage_event table may have inconsistent entries, e.g.:
- STOP entries without a START entry, or DESTROY entries without a CREATE.
- Double entries – i.e. a VM has two START entries.
The usage logs will show where these failures occur. The fix for these issues is to add/delete entries as required in the cloud.usage_event table, e.g. add a VM.START with date stamp if missing and so on.
Usage service logs
The usage service writes all logs to /var/log/cloudstack/usage/usage.log. These logs are relatively verbose and will outline all actions performed during the usage job:
DEBUG [usage.parser.IPAddressUsageParser] (Usage-Job-1:null) (logid:) Parsing IP Address usage for account: 2 DEBUG [usage.parser.IPAddressUsageParser] (Usage-Job-1:null) (logid:) Total usage time 86400000ms DEBUG [usage.parser.IPAddressUsageParser] (Usage-Job-1:null) (logid:) Creating IP usage record with id: 3, usage: 24, startDate: Tue Oct 10 00:00:00 UTC 2017, endDate: Tue Oct 10 23:59:59 UTC 2017, for account: 2 DEBUG [usage.parser.VPNUserUsageParser] (Usage-Job-1:null) (logid:) Parsing all VPN user usage events for account: 2 DEBUG [usage.parser.VPNUserUsageParser] (Usage-Job-1:null) (logid:) No VPN user usage events for this period DEBUG [usage.parser.VMSnapshotUsageParser] (Usage-Job-1:null) (logid:) Parsing all VmSnapshot volume usage events for account: 2 DEBUG [usage.parser.VMSnapshotUsageParser] (Usage-Job-1:null) (logid:) No VM snapshot usage events for this period DEBUG [usage.parser.VMInstanceUsageParser] (Usage-Job-1:null) (logid:) Parsing all VMInstance usage events for account: 3 DEBUG [usage.parser.NetworkUsageParser] (Usage-Job-1:null) (logid:) Parsing all Network usage events for account: 3 DEBUG [usage.parser.VmDiskUsageParser] (Usage-Job-1:null) (logid:) Parsing all Vm Disk usage events for account: 3
Housekeeping of cloud_usage table
To carry out housekeeping of the cloud_usage.cloud_usage table the “RemoveRawUsageRecords” API call can be used to delete all usage entries older than a certain number of dates. Note – since the cloud_usage table only contains completed parsed entries deleting anything from this table will not lead to inconsistencies – rather just cut down on the number of usage records being reported on.
More information can be found in http://cloudstack.apache.org/api/apidocs-4.9/apis/removeRawUsageRecords.html.
The following example deletes all usage records older than 5 days:
# cloudmonkey removeRawUsageRecords interval=5 success = true
Regenerating usage data
The CloudStack API also has a call for regenerating usage records – generateUsageRecords. This can be utilised to rerun the usage job in case of job failure. More information can be found in the CloudStack documentation – http://cloudstack.apache.org/api/apidocs-4.9/apis/generateUsageRecords.html.
Please note the comment on the above documentation page: “This will generate records only if there any records to be generated, i.e. if the scheduled usage job was not run or failed”. In other words this API call should not be made ad-hoc apart from in this specific situation.
# cloudmonkey generateUsageRecords startdate=2017-09-01 enddate=2017-09-30 success = true
Quota service
Anyone looking through the cloud_usage database will notice a number of quota_* tables. These are not directly linked to the usage service itself, they are rather consumed by the Quota service. This service was created to monitor usage of CloudStack resources based on a per account credit limit and a per resource credit cost.
For more information on the Quota service please refer to the official CloudStack documentation / CloudStack wiki:
- https://cwiki.apache.org/confluence/display/CLOUDSTACK/Quota+Service+-+FS
- http://docs.cloudstack.apache.org/projects/cloudstack-administration/en/4.8/plugins/quota.html
Conclusion
The CloudStack usage service can seem complicated for someone just getting started with it. We hope this blog post has managed to explain the background processes and how to get useful data out of the service.
We always value feedback – so if you have any comments or questions around this blog post please feel free to get in touch with the ShapeBlue team.
About The Author
Dag Sonstebo is a Cloud Architect at ShapeBlue, The Cloud Specialists. Dag spends his time designing, implementing and automating IaaS solutions based around Apache CloudStack.
Giles is CEO and founder of ShapeBlue and is responsible for overall company strategy, strategic relationships, finance and sales.
He is also a committer and PMC member of the Apache CloudStack project, and Chairman of the European Cloudstack User Group, actively helping promote brand awareness of the technology.





